고정 헤더 영역
상세 컨텐츠
본문
Attention Is All You Need
논문 링크 : Attention Is All You Need
pytorch code : harvardnlp
1. 배경
기존 좋은 성능의 번역 모델은 RNN, CNN을 사용하였으나 RNN계열의 모델에서는 sequential하게 학습하는 구조로 병렬처리가 어려워 시간이 오래걸리며, 고정된 크기의 벡터에 모든 정보를 압축하여 정보 손실 문제가 있었습니다.(Long term dependency, Vanishing gradient, Fixed context vector) CNN에서는 위치상 거리가 먼 단어간의 관계를 학습하기 위해서는 여러개의 합성곱 층을 쌓아 계산량이 많아지는 단점이 있었습니다.
이러한 문제를 해결하기 위해 제안된 모델이 Transformer입니다. 해당 모델은 기존보다 계산량도 적고 병렬처리가 가능하여 처리속도가 100배 이상 개선되었다고합니다.
2. Attention 이란?
Attention의 기본 아이디어는 단어의 전체적인 정보를 저장하는것으로, decoder에서 출력 단어를 예측하는 매 시점마다 encoder의 전체 입력 문장을 참고하는 것입니다. 전체 입력 문장을 동일한 비율로 참고하는 것은 아니며 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀더 집중(attention)해서 참고합니다. 이를 통해 RNN 기반 모델의 Long term dependency를 해소 할 수 있었습니다.
Attention에서는 decoder가 특정 시점의 단어를 출력할 떄 encoder의 정보 중 연관성이 있는 부분에 주목하여 adaptive context vector를 생성합니다. encoder를 통해 만들어지는 각 Hidden State에 점수를 주고 softmax score로 정규화한 vector(가중치)들을 더하여 context vector로 적용합니다. 또한 encoder의 hidden vector와 decoder의 hidden vector의 내적을 이용하여 score를 구한 뒤 decoder를 통해 번역된 sequence를 생성했습니다. Self-Attention 개념을 이용하여 문장내에 단어 사이를 고려할 수 있으며 Multi-Head Attention을 사용하면 각 Head에 대해 영어에서 사용되는 대명사와 원래 명사를 찾는 역할도 할 수 있습니다.

3. Model Architecture
RNN의 단점을 보완하고자 seq2seq구조에서 attention만을 사용한 것이 Transformer라고하며 해당 논문의 모델구조입니다. Attention이 RNN없이 단어의 위치와 순서정보를 활용 할 수 있는 방법은 Positional encoding 때문입니다. Positional encoding란 sequence 순서 정보, position 정보를 이해하기 위한 개념으로 encoder와 decoder의 입력값마다 상대적인 위치 정보를 더해주는것입니다. Positional encoding은 sin,cos 함수를 통해 출력하여 모든 값이 -1~1사이의 값을 가지게됩니다.

Trnsformer의 구성은 크게 encoder와 decoder로 구분할수 있으며 아래 구조형태입니다.

인코더의 Self-Attention를 살펴보면 아래와 같이 query, key value 벡터로 attention score를 계산하게됩니다.
Attention score = query * key (값이 높을수록 단어의 연관성이 높다)
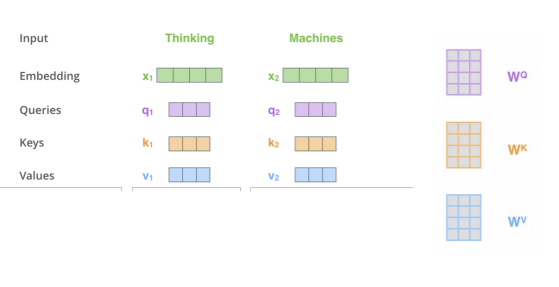
Self-Attention 사용할 경우 다음과같은 이점이 있습니다.
① layer당 연산량 감소 및 병렬처리 가능
② Positional encoding 사용으로 Long term dependency 해소
Encoder Layer
- word embedding 후 positional encoding 적용
- Multi head attention에 입력하여 출력된 여러가지 결과값을 이어붙여 또다른 행렬과 곱해져 결국 최초 word embedding과 동일한 차원의 벡터로 출력하게 되어있습니다.
- 각각의 vector는 따로 fully connected layer로 들어가 입력과 동일한 사이즈의 벡터로 출력합니다.
- 딥러닝 학습 중 역전파에 의해 positional encoding이 손실 될 가능성이 있습니다. 이를 보완하기 위해 Residual Connection으로 입력된 값을 다시한번 더해줍니다.
- Residual Connection뒤에 layer normalization을 사용하여 학습의 효율을 증진시킵니다.
* 입력vector와 출력 vector의 차원이 동일 => encoder layer를 여러개 붙여 사용 가능
Transformer는 6개의 encoder layer를 이어 붙인 형태로 각각의 encoder layer는 서로의 모델 parameter 가중치를 공유하지 않고 따로 학습시킵니다.
Decoder Layer
(encoder와의 차이)
- Masked Multi head Attention layer구조 : 지금까지 출력된 값까지만 attention을 적용하는것
- Multi head attention : 현재 decoder의 입력값을 query, encoder의 출력값을 key와 value로 사용
- Feed Forward layer : encoder와 동일
- decoder 최종단에 linear layer, sofrtmax layer가 존재합니다.
linear layer는 sortmax의 입력 로직을 생성하며 sortmax는 모델이 알고있는 모든 단어들에 대한 확률값을 출력하는
역할을 합니다.
※ Architecture 이해를 위해 참고 사이트
omicro03.medium.com/attention-is-all-you-need-transformer-paper-%EC%A0%95%EB%A6%AC-83066192d9ab
www.youtube.com/watch?v=mxGCEWOxfe8
4. 결론
Transformer는 recurrence와 convolution을 모두 제거하여 attendtion에만 의존하는 새로운 종류의 모델로써 계산량을 줄이고 병렬화를 적용하여 학습속도가 매우 빠르다. Attention에 기반한 모델은 텍스트 뿐만 아니라 이미지, 오디오 등의 상대적으로 큰 입출력을 요하는 task들에 효과적으로 사용가능하다. (예: Stand-Alone Self-Attention in Vision Models)
[참고 자료]
welcome-to-dewy-world.tistory.com/105?category=913368
dmqm.korea.ac.kr/activity/seminar/244
omicro03.medium.com/attention-is-all-you-need-transformer-paper-%EC%A0%95%EB%A6%AC-83066192d9ab
welcome-to-dewy-world.tistory.com/108
'IT > 논문리뷰' 카테고리의 다른 글
| Session-based Recommendations with Recurrent Neural Networks (0) | 2021.06.13 |
|---|





댓글 영역